18.10.2025
Фото: Коллаж Mustafin Magazine
Текст: Руслан Абдряев
Убьет ли искусственный интеллект авторское право
Разбираем судебные иски, цифровых двойников и новые правила игры
В начале октября OpenAI обновила Sora. Теперь приложение работает на модели Sora 2 и генерирует изображения, которые в некоторых случаях нарушают авторские права. Японское правительство даже обратилось к компании с просьбой добровольно перестать нарушать копирайты авторов манги, аниме и видеоигр в своих продуктах.
Этот эпизод – лишь один из многих скандалов вокруг ИИ и авторских прав. Музыканты, писатели, художники и медиа по всему миру требуют от нейросетей не воровать их труд.
Автор Mustafinmag рассмотрел несколько таких кейсов и то, чем это закончилось для владельцев интеллектуальной собственности и разработчиков ИИ-моделей.
Визуальный контент

Коллаж Mustafin Magazine
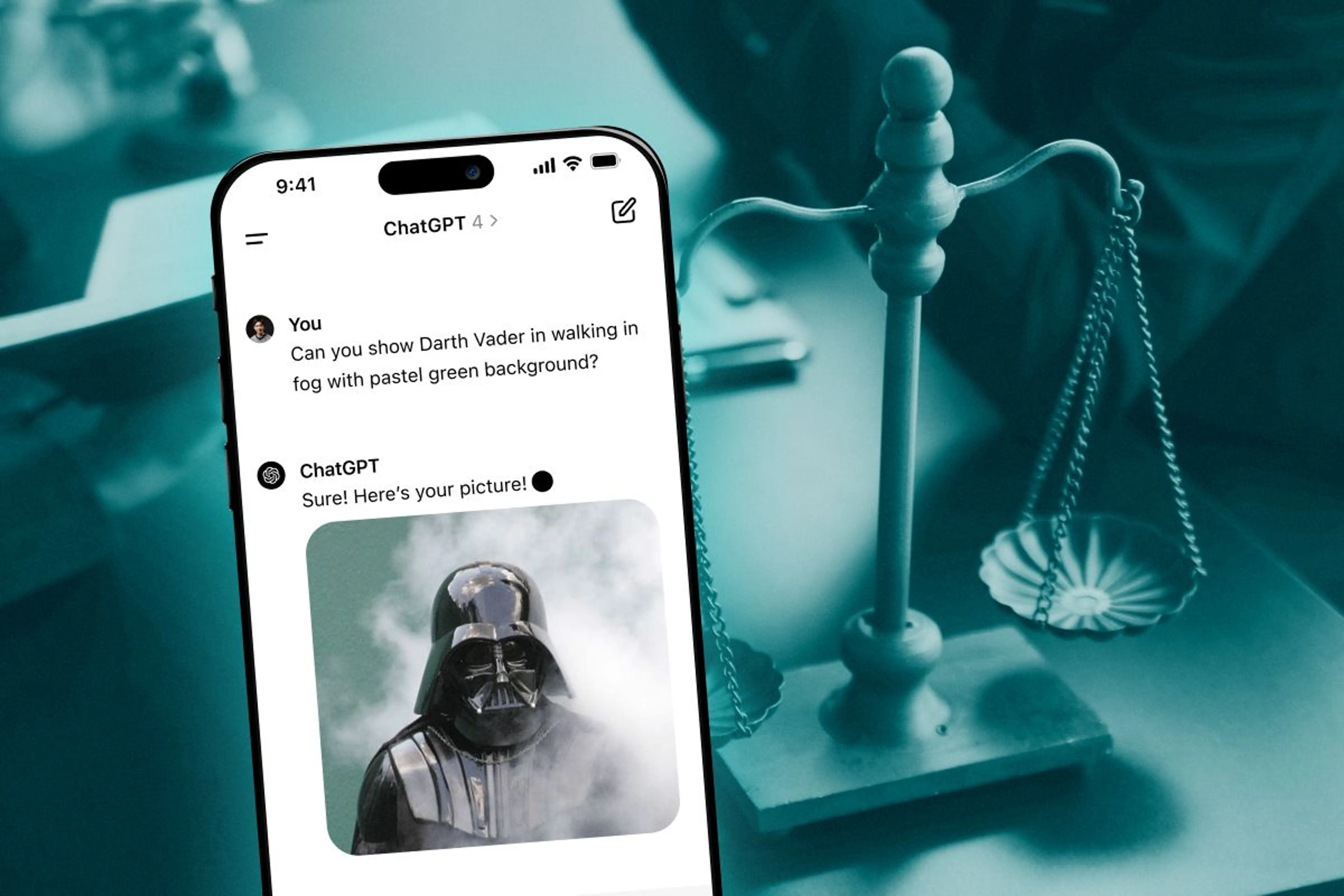
За последние месяцы Midjourney получила несколько исков от Disney, Universal и Warner Bros Discovery. Киностудии обнаружили в выдаче генератора изображений Midjourney Супермена, Скуби-Ду, Дарта Вейдера и других известных персонажей.
Истцы уверены: если ИИ выдает копии их персонажей, значит, нейросеть обучали на оригиналах. В ответ Midjourney никак не реагировала на просьбы студий прекратить нарушение авторских прав, а только выпускала обновления сервиса.
Пока студии подают иски, OpenAI выпустила видеоверсию Sora, после чего в сети появились ролики с персонажами, которых компания точно не лицензировала. При этом разработчик не скрывает, что работает в “серой зоне”.
Чтобы сгладить конфликт, компания пообещала дать правообладателям инструмент для блокировки своих персонажей в выдаче Sora. Как это будет работать – пока неизвестно.

Instagram / therock
Тем временем кинокомпании также экспериментируют с ИИ. Например, Disney пыталась создать цифрового двойника Дуэйна Джонсона для второй “Моаны”, получив согласие актера. Однако юридические сложности не позволили компании добавить кадры с двойником Джонсона в финальный монтаж.
Lionsgate Films и Runaway объявили о планах создавать фильмы и шоу с помощью нейросетей. Однако партнеры сталкиваются с теми же барьерами: слишком мало данных, слишком много авторских прав – даже на собственную библиотеку Lionsgate.

critterz.tv
Кстати, OpenAI тоже не собирается отставать от конкурентов: в 2025 году компания планирует представить в Каннах полнометражный мультфильм Critterz, созданный полностью ИИ. Netflix тоже в деле – аргентинский сериал “Этернавт” стал первым проектом платформы с кадрами, сгенерированными нейросетью.
Книги и новости

Unsplash / Thai Nguyen Anh
В издательском мире дела с ИИ и авторским правом также складываются весьма печально. За последние годы писатели и издательства подали иски против Meta, Perplexity, Microsoft и других. Самый громкий случай произошел с разработчиком Claude – Anthropic.
Компания выкупила миллионы бумажных книг, отсканировала их, обучила свою модель, а затем уничтожила оригиналы. Суд решил, что это не нарушение – книги ведь куплены легально. Тем не менее Anthropic согласилась выплатить $1,5 млрд авторам – крупнейшую компенсацию в истории копирайт-разбирательств. Каждый писатель получит около $3 тыс. за произведение.

Freepik
Похожий кейс и у Meta, которая выиграла суд. Теперь у технологических компаний есть готовый прецедент: обучаться на книгах можно, если они куплены законно. Некоторые компании стараются не допустить юридических проблем. Например, Microsoft предлагает авторам по $5 тыс. за использование их книг в обучении ИИ.
Медиаиндустрия, в свою очередь, готовит новые иски: New York Times, BBC, Rolling Stone и Hollywood Reporter. Пока им лишь удалось заставить OpenAI сохранять записи диалогов пользователей с ChatGPT, поскольку без них сложно доказать, что чат-бот действительно использует чужие тексты.
Музыка

Instagram / beyonce
ИИ уже научился звучать как Бейонсе, Кэти Пэрри и Rolling Stones, а музыкальные лейблы это, конечно же, не оценили. В начале года Anthropic подписала соглашение с ABKCO Records, Universal Music и Concord Music, чтобы не обучать Claude на песнях этих артистов. До этого компании подали иски – минимум по 500 песням, нарушившим права.
Стриминговые площадки также активно борются с ИИ-треками. Например, только за год Spotify удалил более 75 млн таких песен, а Deezer признался, что почти 20% библиотеки сервиса – это треки, созданные ИИ. До этого Sony Music зачистила свыше 75 тыс. дипфейк-песен, с поддельными голосами Бейонсе и Гарри Стайлса.
Куда все идет

Freepik / DC Studio
ИИ ломает систему авторского права, и юристы это понимают. Как объясняет эксперт по интеллектуальной собственности Андрес Гуадамус, ИИ не публикует чужие работы напрямую – он просто учится на данных, а значит, формально ничего не нарушает.
Компании в сфере ИИ собрали данные для обучения своих моделей до возникновения обсуждений авторских прав в этом контексте. Поэтому у правообладателей есть возможность только влиять на выдачу нейросетей точечно и тоже не всегда успешно.
Да и лицензировать все просто невозможно, поскольку датасеты гигантские, а за один запрос к чат-боту правообладатель получал бы 0,00000001% от стоимости подписки. Подобная система нерентабельна экономически и невыполнима технически.
Гуадамус назвал несколько вариантов решений проблем авторского права. Первый – введение налога на ИИ-компании вроде Meta и OpenAI с последующим направлением средств на поддержку авторов
Еще одним вариантом может стать пересмотр закона об авторском праве: создать новые категории прав, которые признают использование произведений в обучении моделей. Кроме того, ИИ-компании могут основать фонды и перечислять туда часть прибыли.
